

Large Language Models (LLMs) have demonstrated remarkable prowess in generating contextually coherent responses, yet their fixed context windows pose fundamental challenges for maintaining consistency over prolonged multi-session dialogues. We introduce Mem0, a scalable memory-centric architecture that addresses this issue by dynamically extracting, consolidating, and retrieving salient information from ongoing conversations. Building on this foundation, we further propose an enhanced variant that leverages graph-based memory representations to capture complex relational structures among conversational elements. Through comprehensive evaluations on LOCOMO benchmark, we systematically compare our approaches against six baseline categories: (i) established memory-augmented systems, (ii) retrieval-augmented generation (RAG) with varying chunk sizes and k-values, (iii) a full-context approach that processes the entire conversation history, (iv) an open-source memory solution, (v) a proprietary model system, and (vi) a dedicated memory management platform. Empirical results show that our methods consistently outperform all existing memory systems across four question categories: single-hop, temporal, multi-hop, and open-domain. Notably, Mem0 achieves 26% relative improvements in the LLM-as-a-Judge metric over OpenAI, while Mem0 with graph memory achieves around 2% higher overall score than the base configuration. Beyond accuracy gains, we also markedly reduce computational overhead compared to full-context method. In particular, Mem0 attains a 91% lower p95 latency and saves more than 90% token cost, offering a compelling balance between advanced reasoning capabilities and practical deployment constraints. Our findings highlight critical role of structured, persistent memory mechanisms for long-term conversational coherence, paving the way for more reliable and efficient LLM-driven AI agents.
1. Introduction
Human memory is a foundation of intelligence—it shapes our identity, guides decision-making, and enables us to learn, adapt, and form meaningful relationships (Craik and Jennings, 1992). Among its many roles, memory is essential for communication: we recall past interactions, infer preferences, and construct evolving mental models of those we engage with (Assmann, 2011). This ability to retain and retrieve information over extended periods enables coherent, contextually rich exchanges that span days, weeks, or even months.
AI agents, powered by large language models (LLMs), have made remarkable progress in generating fluent, contextually appropriate responses (Yu et al., 2024, Zhang et al., 2024). However, these systems arefundamentally limited by their reliance on fixed context windows, which severely restrict their ability to maintain coherence over extended interactions (Bulatov et al., 2022, Liu et al., 2023). This limitation stems from LLMs’ lack of persistent memory mechanisms that can extend beyond their finite context windows. While humans naturally accumulate and organize experiences over time, forming a continuous narrative of interactions, AI systems cannot inherently persist information across separate sessions or after context overflow. The absence of persistent memory creates a fundamental disconnect in human-AI interaction. Without memory, AI agents forget user preferences, repeat questions, and contradict previously established
facts. Consider a simple example illustrated in Figure 1, where a user mentions being vegetarian and avoiding dairy products in an initial conversation. In a subsequent session, when the user asks about dinner recommendations, a system without persistent memory might suggest chicken, completely contradicting the established dietary preferences. In contrast, a system with persistent memory would maintain this critical user information across sessions and suggest appropriate vegetarian, dairy-free options. This common scenario highlights how memory failures can fundamentally undermine user experience and trust.
Beyond conversational settings, memory mechanisms have been shown to dramatically enhance agent performance in interactive environments (Majumder et al., Shinn et al., 2023). Agents equipped with memory of past experiences can better anticipate user needs, learn from previous mistakes, and generalize knowledge across tasks (Chhikara et al., 2023). Research demonstrates that memory-augmented agents improve decision-making by leveraging causal relationships between actions and outcomes, leading to more effective adaptation in dynamic scenarios (Rasmussen et al., 2025). Hierarchical memory architectures (Packer et al., 2023, Sarthi et al., 2024) and agentic memory systems capable of autonomous evolution (Xuet al., 2025) have further shown that memory enables more coherent, long-term reasoning across multiple dialogue sessions.
Unlike humans, who dynamically integrate new information and revise outdated beliefs, LLMs effectively “reset” once information falls outside their context window (Zhang, 2024, Timoneda and Vera, 2025). Even as models like OpenAI’s GPT-4 (128K tokens) (Hurst et al., 2024), o1 (200K context) (Jaech et al., 2024), Anthropic’s Claude 3.7 Sonnet (200K tokens) (Anthropic, 2025), and Google’s Gemini (at least 10M tokens) (Team et al., 2024) push the boundaries of context length, these improvements merely delay rather than solve the fundamental limitation. In practical applications, even these extended context windows prove insufficient for two critical reasons. First, as meaningful human-AI relationships develop over weeks or months, conversation history inevitably exceeds even the most generous context limits. Second, and perhaps more importantly, real-world conversations rarely maintain thematic continuity. A user might mention dietary preferences (being vegetarian), then engage in hours of unrelated discussion about programming tasks, before returning to food-related queries about dinner options. In such scenarios, a full-context approach would need to reason through mountains of irrelevant information, with the critical dietary preferences potentially buried among thousands of tokens of coding discussions. Moreover, simply presenting longer contexts does not ensure effective retrieval or utilization of past information, as attention mechanisms. degrade over distant tokens (Guo et al., 2024, Nelson et al., 2024). This limitation is particularly problematicin high-stakes domains such as healthcare, education, and enterprise support, where maintaining continuity and trust is crucial (Hatalis et al., 2023). To address these challenges, AI agents must adopt memory systems that go beyond static context extension. A robust AI memory should selectively store important information, consolidate related concepts, and retrieve relevant details when needed—mirroring human cognitive processes (He et al., 2024). By integrating such mechanisms, we can develop AI agents that maintain consistent personas, track evolving user preferences, and build upon prior exchanges. This shift will transform AI from transient, forgetful responders into reliable, long-term collaborators, fundamentally redefining the future of conversational intelligence.
In this paper, we address a fundamental limitation in AI systems: their inability to maintain coherent reasoning across extended conversations across different sessions, which severely restricts meaningful long-term interactions with users. We introduce Mem0 (pronounced as mem-zero), a novel memory architecture that dynamically captures, organizes, and retrieves salient information from ongoing conversations. Building on this foundation, we develop Mem0g , which enhances the base architecture with graph-based
memory representations to better model complex relationships between conversational elements. Our experimental results on the LOCOMO benchmark demonstrate that our approaches consistently outperform existing memory systems—including memory-augmented architectures, retrieval-augmented generation (RAG) methods, and both open-source and proprietary solutions—across diverse question types, while simultaneously requiring significantly lower computational resources. Latency measurements further reveal that Mem0 operates with 91% lower response times than full-context approaches, striking an optimal balance between sophisticated reasoning capabilities and practical deployment constraints. These contributions represent a meaningful step toward AI systems that can maintain coherent, context-aware conversations over extended durations—mirroring human communication patterns and opening new possibilities for applications
in personal tutoring, healthcare, and personalized assistance.
2. Proposed Methods
We introduce two memory architectures for AI agents. (1) Mem0 implements a novel paradigm that extracts, evaluates, and manages salient information from conversations through dedicated modules for memory extraction and updation. The system processes a pair of messages between either two user participants or a user and an assistant. (2) Mem0g extends this foundation by incorporating graph-based memory representations, where memories are stored as directed labeled graphs with entities as nodes and relationships as edges. This structure enables a deeper understanding of the connections between entities. By explicitly modeling both entities and their relationships, Mem0g supports more advanced reasoning across interconnected facts, especially for queries that require navigating complex relational paths across multiple memories.
2.1. Mem0
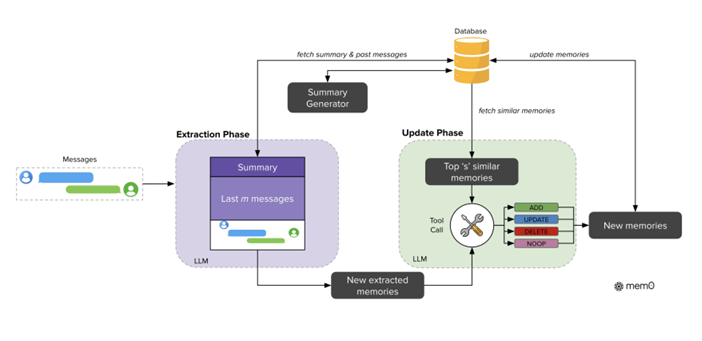
Our architecture follows an incremental processing paradigm, enabling it to operate seamlessly within ongoing conversations. As illustrated in Figure 2, the complete pipeline architecture consists of two phases:extraction and update.The extraction phase initiates upon ingestion of a new message pair (mt−1, mt), where mt represents the current message and mt−1 the preceding one. This pair typically consists of a user message and an assistant response, capturing a complete interaction unit. To establish appropriate context for memory extraction, the
system employs two complementary sources: (1) a conversation summary S retrieved from the database that encapsulates the semantic content of the entire conversation history, and (2) a sequence of recent messages {mt−m, mt−m+1, …, mt−2} from the conversation history, where m is a hyperparameter controlling the recency window. To support context-aware memory extraction, we implement an asynchronous summary generation module that periodically refreshes the conversation summary. This component operates independently of the main processing pipeline, ensuring that memory extraction consistently benefits from up-to-date contextual information without introducing processing delays. While S provides global thematic understanding across the entire conversation, the recent message sequence offers granular temporal context that may contain relevant details not consolidated in the summary. This dual contextual information, combined with the new message pair, forms a comprehensive prompt P = (S, {mt−m, …, mt−2}, mt−1, mt) for an extraction function
ϕ implemented via an LLM. The function ϕ(P) then extracts a set of salient memories Ω = {ω1, ω2, …, ωn} specifically from the new exchange while maintaining awareness of the conversation’s broader context, resulting in candidate facts for potential inclusion in the knowledge base.
Following extraction, the update phase evaluates each candidate fact against existing memories to maintain consistency and avoid redundancy. This phase determines the appropriate memory management operation for each extracted fact ωi ∈ Ω. Algorithm 1, mentioned in Appendix B, illustrates this process. For each fact, the system first retrieves the top s semantically similar memories using vector embeddings from the database. These retrieved memories, along with the candidate fact, are then presented to the LLM through a function-calling interface we refer to as a ‘tool call.’ The LLM itself determines which of four distinct operations to execute: ADD for creation of new memories when no semantically equivalent memory exists; UPDATE for augmentation of existing memories with complementary information; DELETE for removal of memories contradicted by new information; and NOOP when the candidate fact requires no modification to the knowledge base. Rather than using a separate classifier, we leverage the LLM’s reasoning capabilities to directly select the appropriate operation based on the semantic relationship between the candidate fact and existing memories. Following this determination, the system executes the provided operations, thereby maintaining knowledge base coherence and temporal consistency.
Continue reading.https://arxiv.org/pdf/2504.19413.